In today’s world of print nightmare vulnerabilities and security exploits around printing and driver installation, our organization was looking into various ways to mitigate our risk while still allowing our non-admin users to install printers on their computers. After looking at all the options out there, Microsoft’s Universal Print solution seemed like a perfect option. It uses a preinstalled universal printing driver that is native to the OS, and it gets updates through Windows updates. We found there is even support for job-holding and follow me printing through third party addons like the Papercut Universal Print connector, which is free with our existing Papercut subscription.
The big issue with Universal Print is the lack of documentation when it comes to doing things like programmatically installing printers. As an admin who likes having control over all things, I was a bit miffed that I couldn’t find a way to install a Universal Print printer via C#, Powershell or any of the other tools at my disposal. This means that I can neither “push” a printer to a user’s machine, nor build an application to allow them to easily do the job themselves. Microsoft’s only existing solution at the time of writing this article is a convoluted system of csv files, and an .intunewin packaged installer delivered through Intune that will perform a printer installation during a user log on event. There’s a certain inelegance to that method of installation, that I just can’t accept in my life.
Traditional Printing Solution
Currently, users in our organization use a printer management tool I wrote that allows them to select the location they’re at, then pick a printer from a list of printers at that site. A list box is then populated with the list of printers dedicated to that site by querying the print server for that location. They can then install the printer while choosing whether or not to make it their default printer. The app also handles uninstalling printers as well.
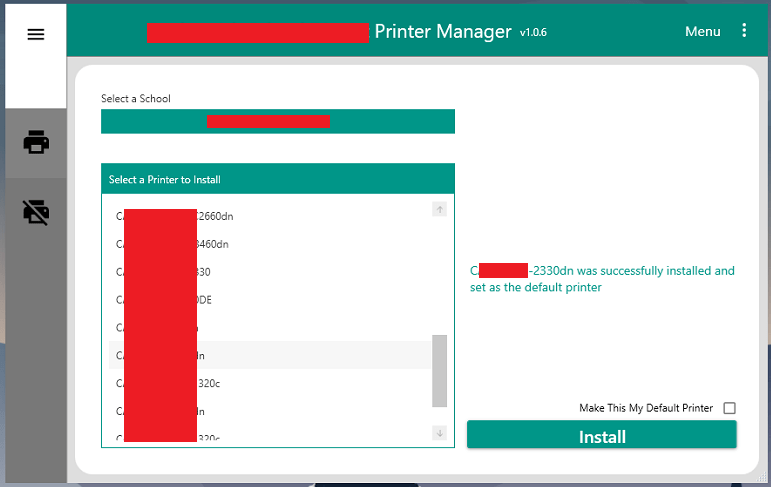
There’s got to be a better way!
I wanted our users to manage printers the same way after we migrated to Universal Print. Traditional printer installation, aka connecting to a shared network print queue, is a well documented .net procedure that was easy to implement. Unfortunately, the same could not be said for Universal Print printer installation. I decided to take the Hail Mary long shot and go hat-in-hand to Microsoft asking for their help. I fully expected them to come back to me with a simple and concise, “No, but thank you for your interest”. Luckily I connected with a very helpful support escalation engineer who did their best to squeeze any nugget of information out of the Universal Print dev team who were, as I expected, reluctant to divulge any useful information. My useful nugget came in the form of three simple word. Windows, devices, enumeration. Knowing that this was as much help as I would receive, I took it and said, “thank you very much”.
Narrowing the scope of my search was all I needed, so I set off and read everything I could about that particular namespace. As it turns out, Universal printers are not truly installed at all. They are paired using the functionality of the Windows.Devices.Enumeration namespace. This is very similar to the process of pairing a Bluetooth device, a WSD device, UPnP device or any other wireless device. After brushing up on all of the related Microsoft documentation I found that Microsoft has a sample pairing application (download this if you’d like to follow along with the code below) written in my preferred language, C#, that was already to set up to pair the most common types of devices. This really helped my understanding of the discovery, and the pairing process. This was also perfect because I now had a basic platform to perform my testing that wouldn’t require me to code it from scratch. I just had to figure out how to actually do the pairing.
On a scale of 1 to 10
I’ll skip over all the days of investigation work I did and get right to the code that worked, and what modifications you can make to Microsoft’s sample pairing application to test the functionality for yourself. I’ll be using the C# version of the sample pairing application if you’re following along. This code supports “scenario 8”, simple device pairing. First, in the DisplayHelper class, I had to create a new DeviceSelectorInfo object. This binds an aqs query string as well as a DeviceInformationKind object to the selectable dropdown box which determines the types of devices which will be searched for. The short explanation of the query is that “~<” is the “begins with” operator. The query runs a search for any AssociationEndpoint with an ID starting with “MCP#”.
//a new DeviceSelectorInfo object for Universal Printers
public static DeviceSelectorInfo UPprinter =>
new DeviceSelectorInfo() { DisplayName = "Universal Print Printer", Selector = "System.Devices.Aep.AepId:~<\"MCP#\"", Kind = DeviceInformationKind.AssociationEndpoint};
Next, the application populates the list of selectable items rather than doing so through direct binding because it uses different DeviceSelectorInfo objects for different scenarios. Because of this, you’ll need to populate the dropdown selector with the newly created DeviceSelctorInfo object. Scroll down in the DisplayHelper class to the public static List named PairingSelectors and add “selectors.Add(UPprinter);”
/// <summary>
/// Selectors for use in the pairing scenarios
/// </summary>
public static List<DeviceSelectorInfo> PairingSelectors
{
get
{
// Add selectors that can be used in pairing scenarios
List<DeviceSelectorInfo> selectors = new List<DeviceSelectorInfo>();
selectors.Add(Bluetooth);
selectors.Add(BluetoothLE);
selectors.Add(WiFiDirect);
selectors.Add(PointOfServicePrinter);
AddVideoCastingIfSupported(selectors);
selectors.Add(Wsd);
selectors.Add(Upnp);
selectors.Add(NetworkCamera);
//New Universal Print Selector
selectors.Add(UPprinter);
return selectors;
}
}The first time I ran the search and I found a bunch of Universal Print printers, I was ecstatic. By placing a few breakpoints in the Watcher_DeviceAdded method of the DeviceWatcherHelper class I could view the DeviceInformation objects that were returned from the query. They contained a device id, and pairing properties to show if the device was able to be paired and if it was paired already. I rushed out to update my printer manager application to support searching for and pairing with Universal Print printers.
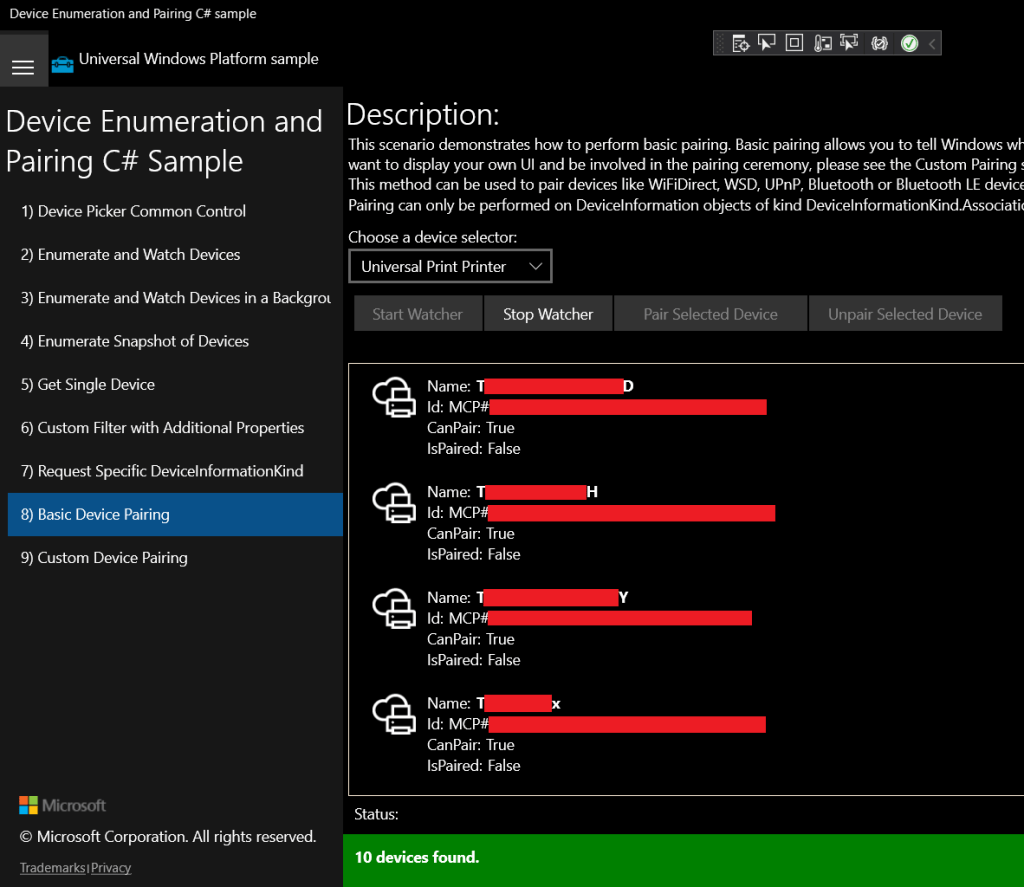
Quickly though, my hopes were dashed when I made an upsetting realization. I had provisioned close to 30 UP printers, but only 10 of them were being found. I spent several days probing for mistakes in the code, and trying various aqs queries. I tried enumerating UP printers via their AssociationEndpointContainer parents, and other various fruitless methods. No matter what I did, my code would only ever find 10 devices. Eventually I found my answer in a support article from Microsoft.
“If the printer is still not in the list of discovered printers, that could be caused by the fact that Windows shows the first 10 printers discovered from Universal Print in the order of their proximity to the user.”
To borrow a phrase from a coworker of mine, “Soul crusher…”. This behavior, for whatever reason, is completely by design.
Where there’s a will
Having used Universal Print in my testing for a few months, I knew that Windows was perfectly capable of enumerating more than 10 printers at a time. The initial search will always return 10 results, but you can click “Search Universal Print for printers” and find the complete list. After some trial and error, I believe I know how they’re doing this. I think the extended list of printers that is returned in the Devices and Printers area of Windows is actually constructed by querying the Graph API. The relevant endpoint here is https://graph.microsoft.com/v1.0/print/shares. A GET request to this endpoint will return a list of all the shares a user has permissions to connect to. This was useful for seeing all the printers I could connect to, but it wasn’t enough on its own to help me install printers that weren’t in the list of 10 devices returned to me by the DeviceWatcher in the sample application.
When I queried the printer shares I noticed something interesting. The ID of each printer share looked suspiciously like the IDs of the AssociationEndpoint DeviceInformation objects that were returned by the application’s DeviceWatcher. If my UP printer share’s ID through the Graph API was 00000000-0000-0000-0000-000000000000, the AssociationEndpoint DeviceInformation object’s ID would be MCP#00000000-0000-0000-0000-000000000000. Basically, every pairing object’s id was simply it’s Graph API ID with the prefix “MCP#”.
From here it just took a little more research to find that I could directly query and single UP printer whether or not it was in the list of 10 devices returned to me by the DeviceWatcher. In fact, the method doesn’t use a DeviceWatcher query at all. Instead it uses the DeviceInformation.CreateFromIdAsync() method of the Windows.Devices.Enumeration namespace to do the heavy lifting. I made a simple method that would take a passed in string in the form of a UP printer share id, create a Deviceinformation object from that id, and use that to pair the device.
/// <summary>
/// Uses the ID of a UP printer share to pair the printer to Windows
/// </summary>
/// <param name="PrinterID"> ID of a printer share retrieved from the Graph API</param>
private async void Pair_UPprinter_From_ID(string PrinterID)
{
//prepend MCP# to the string
string AEPid = "MCP#" + PrinterID;
//retrieve the Deviceinformation object from its ID
var UPPrinter = await DeviceInformation.CreateFromIdAsync(AEPid);
//perform the pairing operation
DevicePairingResult Dpr = await UPPrinter.Pairing.PairAsync();
}When the Pairing.PairAsync() method gets called. The user gets a nice little Windows popup asking if they want to connect to this device, and another window stating the status of the connection attempt.
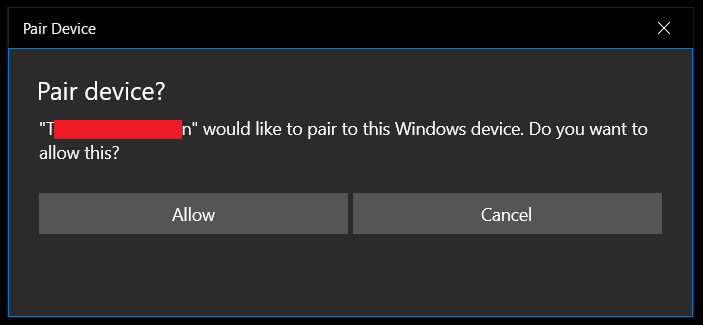
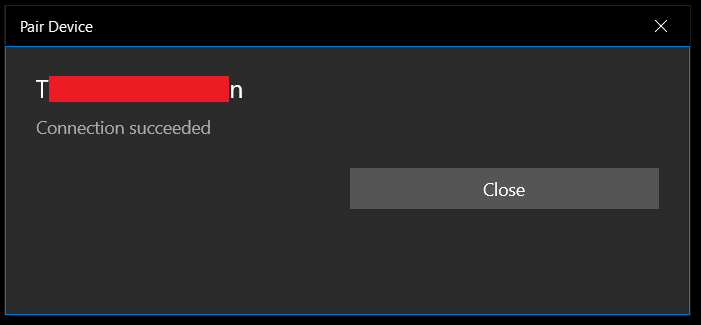
UWP WTF
The big drawback to the above method is that it only works with a UWP application. When you try running the above code in a WPF application the DevicePairingResult will always be failure. The pairing action needs to be approved via the WPF GUI windows shown above. Without that approval, the pairing result is doomed to fail. Luckily, we can get around this issue with a slight adjustment to our code. Instead of using the default DeviceInformation.Pairing.PairAsync() method, you must use DeviceInformation.Pairing.Custom.PairAsync() if you’re not working with a UWP application.
The custom pairing method allows you to intercept pairing request, send it to your own custom UI and handle the “accept” or “deny” inputs from your own GUI. For complete simplicity, I’m going to show a method that simply always passes an “accept” input back to the pairing request without generating a popup or getting any input from the user.
/// <summary>
/// Uses the ID of a UP printer share to pair the printer to Windows
/// </summary>
/// <param name="PrinterID"> ID of a printer share retrieved from the Graph API</param>
private async void Pair_UPprinter_From_ID(string PrinterID)
{
//prepend MCP# to the string
string AEPid = "MCP#" + PrinterID;
//retrieve the Deviceinformation object from its ID
var UPPrinter = await DeviceInformation.CreateFromIdAsync(AEPid);
//add a custom pairing method to handle accepting the request
UPPrinter.Pairing.Custom.PairingRequested += CustomPairingRequest;
//perform the custom pairing operation
DevicePairingResult Dpr = await UPPrinter.Pairing.Custom.PairAsync(DevicePairingKinds.ConfirmOnly, DevicePairingProtectionLevel.None);
//remove the custom pairing method
UPPrinter.Pairing.Custom.PairingRequested -= CustomPairingRequest;
}
//A method to handle accepting the pairing request for non-UWP apps
public void CustomPairingRequest(DeviceInformationCustomPairing sender,DevicePairingRequestedEventArgs args)
{
args.Accept();
}
And that’s pretty much all there is to say about that. Given the above information, you should be able to construct an application or script in any language that can handle installing Universal Print printers on demand.